UNIVARIATEプロシジャ
- 概要
-
入門ガイド

-
構文
-
詳細欠損値丸め記述統計量モードの計算パーセント点の計算位置の検定正規分布のパラメータに対する信頼限界ロバスト推定量ラインプリンタプロットの作成高解像度グラフの作成CLASSステートメントを使用した比較プロットの作成インセットの配置当てはめた連続分布の計算式適合度検定核密度推定Q-Qプロットと確率プロットの作成Q-Qプロットと確率プロットの解釈確率プロットとQ-Qプロットの分布Q-Qプロットを使用した形状パラメータの推定Q-Qプロットを使用した位置パラメータと尺度パラメータの推定Q-Qプロットを使用したパーセント点の推定入力データセットOUTPUTステートメントのOUT=出力データセットOUTHISTOGRAM=出力データセットOUTKERNEL=出力データセットOUTTABLE=出力データセット要約統計量のテーブルODSテーブル名当てはめた分布のODSテーブルODS Graphics計算リソース
-
例複数の変数に対する記述統計量の計算モードの計算極値オブザベーションと極値の表示度数表の作成基本要約プロットの作成FREQ変数を使用したデータセットの分析OUT=出力データセットへの要約統計量の保存出力データセットへのパーセント点の保存平均、標準偏差、分散に対する信頼限界の計算分位点とパーセント点に対する信頼限界の計算ロバスト推定の計算位置の検定ペアのデータを使用した符号検定の実行ヒストグラムの作成一元比較ヒストグラムの作成二元比較ヒストグラムの作成記述統計量を含むインセットの追加ヒストグラムのビン幅の指定正規曲線をヒストグラムに追加する当てはめた正規曲線を比較ヒストグラムに追加するベータ曲線の当てはめ対数正規曲線、Weibull曲線、ガンマ曲線の当てはめ核密度推定の計算3パラメータ対数正規曲線の当てはめ折り重ねられた正規曲線の追加表示対数正規確率プロットの作成対数正規分布の当てはめを表示するヒストグラムの作成正規分位点プロットの作成分布参照線の追加正規分位点プロットの解釈対数正規分位点プロットから3パラメータを推定する対数正規分位点プロットからパーセント点を推定する対数正規分位点プロットからパラメータを推定するWeibull分布の分位点プロットの比較累積分布プロットの作成P-Pプロットの作成
- リファレンス
OUTPUTステートメントは、統計量とBY変数を出力データセットに保存します。BYステートメントを使用する場合、出力データセットの各オブザベーションはBYグループのいずれか1つに対応します。それ以外の場合、出力データセットには1つのオブザベーションのみが含まれます。
OUTPUTステートメントは、UNIVARIATEプロシジャ内でいくつでも使用できます。OUTPUTステートメントごとに、そのステートメントで指定した統計量を含む新しいデータセットが作成されます。VARステートメントをOUTPUTステートメントとともに使用する必要があります。OUTPUTステートメントには、キーワード=名前形式の指定か、またはPCTLPTS=オプションおよびPCTLPRE=オプションの指定が含まれている必要があります。例4.7および例4.8を参照してください。
OUT=オプションを使用すると、出力データセットの名前を指定できます。
キーワード=名前形式の指定では、出力データセットに含める統計量を選択し、その統計量を含む新しい変数に名前を付けることができます。目的の統計量ごとにkeywordを指定し、その後ろに、等号と、統計量を格納する変数であるnamesを指定します。出力データセットでは、OUTPUTステートメントのキーワードの後ろのリストの最初の変数にVARステートメントのリストの最初の変数の統計量が格納され、2番目の変数にVARステートメントの2番目の変数の統計量が格納されます。等号に続くnamesのリストがVARステートメントの変数のリストより短い場合、プロシジャは、VARステートメントにリストされている変数の順番でnamesを使用します。利用できるキーワードを表4.14に示します。
表4.14: 統計キーワード
|
キーワード |
説明 |
|---|---|
|
記述統計キーワード |
|
|
CSS |
修正済み平方和 |
|
CV |
変動係数 |
|
GEOMEAN |
幾何平均 |
|
KURTOSIS|KURT |
尖度 |
|
MAX |
最大値 |
|
MEAN |
標本平均 |
|
MIN |
最小値 |
|
MODE |
最も度数の高い値 |
|
N |
標本サイズ |
|
NMISS |
欠損値の数 |
|
NOBS |
オブザベーションの数 |
|
RANGE |
範囲 |
|
SKEWNESS|SKEW |
歪度 |
|
STD | STDDEV |
標準偏差 |
|
STDMEAN | STDERR |
平均の標準誤差 |
|
SUM |
オブザベーションの合計 |
|
SUMWGT |
重みの合計 |
|
USS |
無修正平方和 |
|
VAR |
分散 |
|
分位点統計キーワード |
|
|
P1 |
1番目のパーセント点 |
|
P5 |
5番目のパーセント点 |
|
P10 |
10番目のパーセント点 |
|
Q1 | P25 |
下位四分位点(25番目のパーセント点) |
|
MEDIAN | Q2 | P50 |
中央値(50番目のパーセント点) |
|
Q3 | P75 |
上位四分位点(75番目のパーセント点) |
|
P90 |
90番目のパーセント点 |
|
P95 |
95番目のパーセント点 |
|
P99 |
99番目のパーセント点 |
|
QRANGE |
四分位範囲(Q3–Q1) |
|
ロバスト統計量キーワード |
|
|
GINI |
Giniの平均差 |
|
MAD |
中央絶対偏差 |
|
QN |
|
|
SN |
|
|
STD_GINI |
Giniの標準偏差 |
|
STD_MAD |
MAD標準偏差 |
|
STD_QN |
|
|
STD_QRANGE |
四分位範囲標準偏差 |
|
STD_SN |
|
|
仮説検定キーワード |
|
|
MSIGN |
符号統計量 |
|
NORMALTEST |
正規性の検定 |
|
SIGNRANK |
符号付き順位統計量 |
|
PROBM |
符号検定でのより大きな絶対値の確率 |
|
PROBN |
正規性の検定の確率値 |
|
PROBS |
符号付き順位検定の確率値 |
|
PROBT |
スチューデントのt検定の確率値 |
|
T |
スチューデントのt検定の統計量 |
UNIVARIATEプロシジャは、データの1番目、5番目、10番目、25番目、50番目、75番目、90番目、95番目、99番目のパーセント点を自動的に計算します。keyword=namesの指定を使用して、これらを出力データセットに保存できます。追加のパーセント点を要求するにはPCTLPTS=オプションを使用できます。次に示すpercentile-optionsは、このような追加のパーセント点に関係します。
-
CIPCTLDF=(cipctl-options)
CIQUANTDF=(cipctl-options) -
PCTLPTS=オプションで要求されるパーセント点の分布によらない信頼限界を要求します。つまり、正規分布などのパラメトリックな分布データを前提としません。UNIVARIATEプロシジャは、Hahn and Meeker (1991)の説明に基づき、順序統計量(順位)を使用して信頼限界を計算します。このオプションは、WEIGHT ステートメントを使用する場合には適用されません。 cipctl-optionsには次のオプションを指定できます。
-
ALPHA=

-
有意水準
( 信頼区間)を指定します。値は、0から1までの間でなければなりません。デフォルト値は0.05であり、これは95%の信頼区間を生成します。デフォルト値は、PROCステートメントで指定された
ALPHA=
の値になります。
信頼区間)を指定します。値は、0から1までの間でなければなりません。デフォルト値は0.05であり、これは95%の信頼区間を生成します。デフォルト値は、PROCステートメントで指定された
ALPHA=
の値になります。
- LOWERPRE=prefixes
-
下側信頼限界を含む変数の名前の作成に使用される1つまたは複数の接頭辞を指定します。複数の分析変数に下側信頼限界を保存するには、接頭辞のリストを指定します。接頭辞の順序は、VARステートメント内の分析変数の順序に対応しています。
- LOWERNAME=suffixes
-
下側信頼限界を含む変数の名前の作成に使用される1つまたは複数の接尾辞を指定します。UNIVARIATEプロシジャは、LOWERPRE=値と接尾辞名を組み合わせて変数名を作成します。接尾辞は要求されたパーセント点に関連付けられているため、PCTLPTS=に指定したパーセント点と同じ順序でリストされます。
- TYPE=keyword
-
信頼限界の種類を指定します。keywordには、LOWER、UPPER、SYMMETRIC、ASYMMETRICのいずれかを指定できます。デフォルト値はSYMMETRICです。
- UPPERPRE=prefixes
-
上側信頼限界を含む変数の名前の作成に使用される1つまたは複数の接頭辞を指定します。複数の分析変数に上側信頼限界を保存するには、接頭辞のリストを指定します。接頭辞の順序は、VARステートメント内の分析変数の順序に対応しています。
- UPPERNAME=suffixes
-
上側信頼限界を含む変数の名前の作成に使用される1つまたは複数の接尾辞を指定します。UNIVARIATEプロシジャは、UPPERPRE=値と接尾辞名を組み合わせて変数名を作成します。接尾辞は要求されたパーセント点に関連付けられているため、PCTLPTS=に指定したパーセント点と同じ順序でリストされます。
注: 接頭辞、パーセント点の値、接尾辞を使用して変数名を作成する方法に関する詳細は、PCTLPTS=、PCTLPRE=、PCTLNAME=オプションの項目を参照してください。
-
ALPHA=
-
CIPCTLNORMAL=(cipctl-options)
CIQUANTNORMAL=(cipctl-options) -
PCTLPTS=オプションで要求されるパーセント点においてデータが正規分布に従うという仮説に基づく信頼限界を要求します。計算方法は、 Hahn and Meeker (1991)のセクション4.4.1で説明されており、t Odeh and Owen (1980)によって提唱された非心分布を使用します。このオプションは、WEIGHT ステートメントを使用する場合には適用されません。 cipctl-optionsには次のオプションを指定できます。
-
ALPHA=
-
有意水準
(信頼区間)を指定します。値は、0から1までの間でなければなりません。デフォルト値は0.05であり、これは95%の信頼区間を生成します。デフォルト値は、PROCステートメントで指定された
ALPHA=
の値になります。
- LOWERPRE=prefixes
-
下側信頼限界を含む変数の名前の作成に使用される1つまたは複数の接頭辞を指定します。複数の分析変数に下側信頼限界を保存するには、接頭辞のリストを指定します。接頭辞の順序は、VARステートメント内の分析変数の順序に対応しています。
- LOWERNAME=suffixes
-
下側信頼限界を含む変数の名前の作成に使用される1つまたは複数の接尾辞を指定します。UNIVARIATEプロシジャは、LOWERPRE=値と接尾辞名を組み合わせて変数名を作成します。接尾辞は要求されたパーセント点に関連付けられているため、PCTLPTS=に指定したパーセント点と同じ順序でリストされます。
- TYPE=keyword
-
信頼限界の種類を指定します。keywordには、LOWER、UPPER、TWOSIDEDのいずれかを指定できます。デフォルト値はTWOSIDEDです。
- UPPERPRE=prefixes
-
上側信頼限界を含む変数の名前の作成に使用される1つまたは複数の接頭辞を指定します。複数の分析変数に上側信頼限界を保存するには、接頭辞のリストを指定します。接頭辞の順序は、VARステートメント内の分析変数の順序に対応しています。
- UPPERNAME=suffixes
-
上側信頼限界を含む変数の名前の作成に使用される1つまたは複数の接尾辞を指定します。UNIVARIATEプロシジャは、UPPERPRE=値と接尾辞名を組み合わせて変数名を作成します。接尾辞は要求されたパーセント点に関連付けられているため、PCTLPTS=に指定したパーセント点と同じ順序でリストされます。
注: 接頭辞、パーセント点の値、接尾辞を使用して変数名を作成する方法に関する詳細は、PCTLPTS=、PCTLPRE=、PCTLNAME=オプションの項目を参照してください。
-
ALPHA=
- PCTLGROUP=BYSTAT | BYVAR
-
VARステートメントで複数の分析変数をリストする場合に、PCTLPTS=オプションで要求する変数がOUT=データセットに追加される順序を指定します。デフォルトでは(またはPCTLGROUP=BYSTATを指定した場合)、パーセント点の値に関連付けられているすべての変数が連続して作成されます。PCTLGROUP=BYVARを指定すると、分析変数に関連付けられているすべての変数が連続して作成されます。
たとえば、次のステートメントを考えます。
proc univariate data=Score; var PreTest PostTest; output out=ByStat pctlpts=20 40 pctlpre=Pre_ Post_; output out=ByVar pctlgroup=byvar pctlpts=20 40 pctlpre=Pre_ Post_; run;
データセット
ByStat内の変数の順序は、Pre_20、Post_20、Pre_40、Post_40です。データセットByVar内の変数の順序は、Pre_20、Pre_40、Post_20、Post_40です。 - PCTLNAME=suffixes
-
PCTLPTS=パーセント点が格納される変数の名前を作成するために、接尾辞を1つ以上指定します。UNIVARIATEプロシジャは、PCTLPRE=値と接尾辞名を組み合わせて変数名を作成します。接尾辞名は、要求されたパーセント点に割り当てられます。このため、接尾辞名は、PCTLPTS=パーセント点と同じ順序で指定してください。PCTLNAME=オプションでn個のsuffixesを指定し、PCTLPTS=オプションでm個のパーセント点の値を指定する場合、
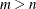 ならば、最初のn個のパーセント点の名前にはsuffixesが使用され、残りの
ならば、最初のn個のパーセント点の名前にはsuffixesが使用され、残りの 個のパーセント点にはデフォルト名が使用されます。たとえば、次のステートメントを考えます。
個のパーセント点にはデフォルト名が使用されます。たとえば、次のステートメントを考えます。
proc univariate; var Length Width Height; output pctlpts = 20 40 pctlpre = pl pw ph pctlname = twenty; run;PCTLNAME=オプションの値twentyは、PCTLPTS=リストの最初のパーセント点に対してのみ使用されます。PCTLPRE=オプションの値にこの接尾辞を付加して、新しい変数名
pltwenty、pwtwentyおよびphtwentyが作成されます。それぞれ、Length、WidthおよびHeightの20番目のパーセント点が格納されます。PCTLNAME=接尾辞の指定は1つのみであるため、Length、WidthおよびHeightの40番目のパーセント点に対する変数名は、接頭辞とパーセント点の値を使用して作成されます。つまり、出力データセットには、変数pltwenty、pl40、pwtwenty、pw40、phtwenty、ph40が含まれます。PCTLPTS=パーセント点が格納される変数の接頭辞名を指定するには、PCTLPRE=を指定する必要があります。
PCTLNAME=値の数がパーセント点の数より少ない場合やPCTLNAME=を省略した場合は、UNIVARIATEプロシジャはパーセント点を接尾辞に使用して、パーセント点を格納する変数の名前を作成します。パーセント点が整数の場合は、パーセント点が使用されます。それ以外の場合は、パーセント点は小数点以下2桁の小数に切り捨てられ、小数点がアンダースコアに置き換えられます。
接頭辞と接尾辞の組み合わせまたは接頭辞とパーセント点の組み合わせが32文字を超える場合は、変数名が32文字になるように接頭辞名が切り捨てられます。
- PCTLNDEC=value
-
パーセント点の変数名に取り込まれるパーセント点の値の小数点桁数を指定します。デフォルト値は2です。たとえば、次のステートメントは、パーセント点の変数を1つずつ含む出力データセットを2つ作成します。データセット
short内の変数名は、pwid85_12になり、データセットlong内の変数名はpwid85_125になります。proc univariate; var width; output out=short pctlpts=85.125 pctlpre=pwid; output out=long pctlpts=85.125 pctlpre=pwid pctlndec=3; run;
- PCTLPRE=prefixes
-
PCTLPTS=パーセント点が格納される変数の名前を作成するために、接頭辞を1つ以上指定します。複数の分析変数に対して同じパーセント点を保存するには、接頭辞のリストを指定します。接頭辞の順序は、VARステートメント内の分析変数の順序に対応しています。 PCTLPRE=およびPCTLPTS=の両オプションを指定する必要があります。
新しい変数名は、prefixとパーセント点の値を使用してプロシジャにより生成されます。指定されたパーセント点が整数の場合は、prefixの後ろに値が付いたものがそのまま変数名になります。指定された値が整数以外の場合は、変数名では小数点がアンダースコアに置き換えられ、小数点以下1桁の小数値に切り捨てられます。たとえば、次のステートメントは、
Widthの20番目、33.33番目、66.67番目、80番目の各パーセント点の変数pwid20、pwid33_3、pwid66_6、pwid80を作成します。proc univariate noprint; var Width; output pctlpts=20 33.33 66.67 80 pctlpre=pwid; run;
複数の変数のパーセント点を要求する場合は、VARステートメントの変数の出現順と同じ順番で、接頭辞をリストする必要があります。prefixとパーセント点の値を結合してできる名前の長さが32文字を超える場合、変数名が32文字になるように接頭辞が切り捨てられます。
- PCTLPTS=percentiles
-
UNIVARIATEプロシジャで自動的に計算されないパーセント点を1つ以上指定します。PCTLPRE=およびPCTLPTS=の両オプションを指定する必要があります。パーセント点は、start TO stop BY increment形式の式で指定できます。startは開始番号、stopは終了番号、incrementは増分値です。PCTLPTS=オプションは、追加のパーセント点を作成してデータセットへ出力します。これらの追加のパーセント点は表示されません。
50番目、95番目、97.5番目、および100番目のパーセント点を計算するには、次のステートメントをサブミットします。
output pctlpre=P_ pctlpts=50,95 to 100 by 2.5;
要求したパーセント点は、PROC UNIVARIATEステートメントのPCTLDEF=オプションで指定した方法に基づいて計算されます。PCTLPRE= (オプションで、PCTLNAME=)を使用して、パーセント点の変数名を指定する必要があります。たとえば、次のステートメントは、分析変数
PreTestおよびPostTestの20番目と40番目のパーセント点を格納する、Pctlsという名前の出力データセットを作成します。proc univariate data=Score; var PreTest PostTest; output out=Pctls pctlpts=20 40 pctlpre=PreTest_ PostTest_ pctlname=P20 P40; run;UNIVARIATEプロシジャは、
PreTestおよびPostTestに関する20番目と40番目のパーセント点を、変数PreTest_P20、PostTest_P20、PreTest_P40、PostTest_P40に保存します。