UNIVARIATEプロシジャ
- 概要
-
入門ガイド

-
構文
-
詳細欠損値丸め記述統計量モードの計算パーセント点の計算位置の検定正規分布のパラメータに対する信頼限界ロバスト推定量ラインプリンタプロットの作成高解像度グラフの作成CLASSステートメントを使用した比較プロットの作成インセットの配置当てはめた連続分布の計算式適合度検定核密度推定Q-Qプロットと確率プロットの作成Q-Qプロットと確率プロットの解釈確率プロットとQ-Qプロットの分布Q-Qプロットを使用した形状パラメータの推定Q-Qプロットを使用した位置パラメータと尺度パラメータの推定Q-Qプロットを使用したパーセント点の推定入力データセットOUTPUTステートメントのOUT=出力データセットOUTHISTOGRAM=出力データセットOUTKERNEL=出力データセットOUTTABLE=出力データセット要約統計量のテーブルODSテーブル名当てはめた分布のODSテーブルODS Graphics計算リソース
-
例複数の変数に対する記述統計量の計算モードの計算極値オブザベーションと極値の表示度数表の作成基本要約プロットの作成FREQ変数を使用したデータセットの分析OUT=出力データセットへの要約統計量の保存出力データセットへのパーセント点の保存平均、標準偏差、分散に対する信頼限界の計算分位点とパーセント点に対する信頼限界の計算ロバスト推定の計算位置の検定ペアのデータを使用した符号検定の実行ヒストグラムの作成一元比較ヒストグラムの作成二元比較ヒストグラムの作成記述統計量を含むインセットの追加ヒストグラムのビン幅の指定正規曲線をヒストグラムに追加する当てはめた正規曲線を比較ヒストグラムに追加するベータ曲線の当てはめ対数正規曲線、Weibull曲線、ガンマ曲線の当てはめ核密度推定の計算3パラメータ対数正規曲線の当てはめ折り重ねられた正規曲線の追加表示対数正規確率プロットの作成対数正規分布の当てはめを表示するヒストグラムの作成正規分位点プロットの作成分布参照線の追加正規分位点プロットの解釈対数正規分位点プロットから3パラメータを推定する対数正規分位点プロットからパーセント点を推定する対数正規分位点プロットからパラメータを推定するWeibull分布の分位点プロットの比較累積分布プロットの作成P-Pプロットの作成
- リファレンス
UNIVARIATEプロシジャは分位点統計量を計算するため、メモリ内にデータのコピーを保存するための追加のメモリを必要とします。デフォルトでは、MEANS、SUMMARYおよびTABULATEプロシジャは分位点を自動的に計算しないため、必要なメモリは少なくなります。これらのプロシジャでは、固定メモリにより分位点を推定する新しい方法を使用するオプションも指定できます。通常、この方法を使用するとメモリ消費量は少なくなります。
UNIVARIATEプロシジャで、分析できる変数の数を制限する唯一の要素は、使用できるコンピュータリソースです。必要な一時記憶域のサイズとCPU時間は、指定するステートメントおよびオプションによって異なります。プロシジャが必要とするコンピュータリソースを計算するには、次のように指定します。
|
N |
データセットのオブザベーションの数 |
|
V |
VARステートメントの変数の数 |
|
|
はi番目の変数の重複しない値の数 |
この場合、すべての変数を処理するための最低メモリ要件(バイト)は![]() です。Mバイトが使用可能でない場合、UNIVARIATEプロシジャですべての統計量を計算するには、データを複数回処理する必要があります。これにより、最小メモリ要件は
です。Mバイトが使用可能でない場合、UNIVARIATEプロシジャですべての統計量を計算するには、データを複数回処理する必要があります。これにより、最小メモリ要件は![]() に減少します。
に減少します。
ROUND=オプションを使用すると重複しない値の数![]() が減少するため、メモリ要件が減少します。ROBUSTSCALEオプションでは、
が減少するため、メモリ要件が減少します。ROBUSTSCALEオプションでは、![]() バイトの一時記憶域が必要です。
バイトの一時記憶域が必要です。
CPU時間にはいくつかの要素が影響します。
-
オブザベーションを内部的に保存するためのVツリー構造を作成する時間は、
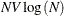 に比例します。
に比例します。
-
積率とi番目の変数の分位点を計算する時間は、
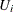 に比例します。
に比例します。
-
NORMALオプションの検定統計量を計算する時間は、Nに比例します。
-
ROBUSTSCALEオプションの検定統計量を計算する時間は、
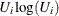 に比例します。
に比例します。
-
符号順位統計量の正確な有意水準を計算する時間は、0以外の値の数が20個以下の場合は長くなる場合があります。
これらの比例定数は要素ごとに異なります。CPUパフォーマンスとメモリ使用量の最適化の詳細は、使用している動作環境のSASドキュメントを参照してください。