UNIVARIATEプロシジャ
- 概要
-
入門ガイド

-
構文
-
詳細
欠損値 丸め 記述統計量 モードの計算 パーセント点の計算 位置の検定 正規分布のパラメータに対する信頼限界 ロバスト推定量 ラインプリンタプロットの作成 高解像度グラフの作成 CLASSステートメントを使用した比較プロットの作成 インセットの配置 当てはめた連続分布の計算式 適合度検定 核密度推定 Q-Qプロットと確率プロットの作成 Q-Qプロットと確率プロットの解釈 確率プロットとQ-Qプロットの分布 Q-Qプロットを使用した形状パラメータの推定 Q-Qプロットを使用した位置パラメータと尺度パラメータの推定 Q-Qプロットを使用したパーセント点の推定 入力データセット OUTPUTステートメントのOUT=出力データセット OUTHISTOGRAM=出力データセット OUTKERNEL=出力データセット OUTTABLE=出力データセット 要約統計量のテーブル ODSテーブル名 当てはめた分布のODSテーブル ODS Graphics 計算リソース
-
例
複数の変数に対する記述統計量の計算 モードの計算 極値のオブザベーションと極値の表示 度数表の作成 ラインプリンタ出力プロットの作成 FREQ変数を使用したデータセットの分析 OUT=出力データセットへの要約統計量の保存 出力データセットへのパーセント点の保存 平均、標準偏差、分散に対する信頼限界の計算 分位点とパーセント点に対する信頼限界の計算 ロバスト推定の計算 位置の検定 対応のあるデータを使用した符号検定の実行 ヒストグラムの作成 一元比較ヒストグラムの作成 二元比較ヒストグラムの作成 記述統計量を含むインセットの追加 ヒストグラムのビン幅の指定 正規曲線をヒストグラムに追加する 当てはめた正規曲線を比較ヒストグラムに追加する ベータ曲線の当てはめ 対数正規曲線、Weibull曲線、ガンマ曲線の当てはめ 核密度推定の計算 3パラメータ対数正規曲線の当てはめ 折り重ねられた正規曲線の追加表示 対数正規確率プロットの作成 対数正規分布の当てはめを表示するヒストグラムの作成 正規確率プロットの作成 分布の参照線の追加 正規確率プロットの解釈 対数正規確率プロットから3パラメータを推定する 対数正規確率プロットからパーセント点を推定する 対数正規確率プロットからパラメータを推定する Weibull分布の分位点プロットの比較 累積分布プロットの作成 P-Pプロットの作成
- リファレンス
| OUTTABLE=出力データセット |
OUTTABLE=データセットは1変量統計量を、分析変数ごとに1つのオブザベーションを含むデータセットに保存します。次の変数が保存されます。
変数 |
説明 |
|---|---|
_CSS_ |
修正済み平方和 |
_CV_ |
変動係数 |
_GINI_ |
Giniの平均差 |
_KURT_ |
尖度 |
_MAD_ |
中央絶対偏差 |
_MAX_ |
最大 |
_MEAN_ |
平均 |
_MEDIAN_ |
中央値 |
_MIN_ |
最小 |
_MODE_ |
モード |
_MSIGN_ |
符号検定 |
_NMISS_ |
欠損値を含まないオブザベーションの数 |
_NOBS_ |
非欠損オブザベーションの数 |
_NORMAL_ |
正規性の検定 |
_P1_ |
|
_P5_ |
|
_P10_ |
|
_P90_ |
|
_P95_ |
|
_P99_ |
|
_PROBM_ |
符号統計量のp値 |
_PROBN_ |
正規性の検定のp値 |
_PROBS_ |
符号付き順位検定のp値 |
_PROBT_ |
t統計量のp値 |
_Q1_ |
|
_Q3_ |
|
_QN_ |
|
_QRANGE_ |
四分位範囲(上位四分位点と下位四分位点の差) |
_RANGE_ |
range |
_SGNRNK_ |
中心化された符号順位 |
_SKEW_ |
歪度 |
_SN_ |
|
_STD_ |
標準偏差 |
_STDGINI_ |
Giniの標準偏差 |
_STDMAD_ |
MAD標準偏差 |
_STDMEAN_ |
平均の標準誤差 |
_STDQN_ |
|
_STDQRANGE_ |
四分位範囲標準偏差 |
_STDSN_ |
|
_SUMWGT_ |
重みの合計 |
_SUM_ |
合計 |
_T_ |
スチューデントのt統計量 |
_USS_ |
無修正平方和 |
_VARI_ |
variance |
_VAR_ |
変数名 |
 番目のパーセント点
番目のパーセント点 番目のパーセント点
番目のパーセント点  番目のパーセント点
番目のパーセント点 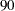 番目のパーセント点
番目のパーセント点  番目のパーセント点
番目のパーセント点 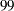 番目のパーセント点
番目のパーセント点  番目のパーセント点(下位四分位点)
番目のパーセント点(下位四分位点) 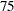 番目のパーセント点(上位四分位点)
番目のパーセント点(上位四分位点) 
 (
(OUTTABLE=データセットとOUT=データセット(OUTPUTステートメントのOUT=出力データセットのセクションを参照)には基本的に同じ情報が含まれます。ただし、OUTTABLE=データセットの構造は、UNIVARIATEプロシジャの同じ呼び出しで複数の分析変数の要約統計量を計算する場合に、より適している場合があります。OUTTABLE=データセット内のオブザベーションはそれぞれ異なる分析変数に対応し、データセット内の変数は要約統計量とインデックスに対応します。
たとえば、10個の分析変数(P1~P10)があるとします。次のステートメントは、これらの各変数の要約統計量を含む、Tableという名前のOUTTABLE=データセットを作成します。
data Analysis; input A1-A10; datalines; 72 223 332 138 110 145 23 293 353 458 97 54 61 196 275 171 117 72 81 141 56 170 140 400 371 72 60 20 484 138 124 6 332 493 214 43 125 55 372 30 152 236 222 76 187 126 192 334 109 546 5 260 194 277 176 96 109 184 240 261 161 253 153 300 37 156 282 293 451 299 128 121 254 297 363 132 209 257 429 295 116 152 331 27 442 103 80 393 383 94 43 178 278 159 25 180 253 333 51 225 34 128 182 415 524 112 13 186 145 131 142 236 234 255 211 80 281 135 179 11 108 215 335 66 254 196 190 363 226 379 62 232 219 474 31 139 15 56 429 298 177 218 275 171 457 146 163 18 155 129 0 235 83 239 398 99 226 389 498 18 147 199 324 258 504 2 218 295 422 287 39 161 156 198 214 58 238 19 231 548 120 42 372 420 232 112 157 79 197 166 178 83 238 492 463 68 46 386 45 81 161 267 372 296 501 96 11 288 330 74 14 2 52 81 169 63 194 161 173 54 22 181 92 272 417 94 188 180 367 342 55 248 214 422 133 193 144 318 271 479 56 83 169 30 379 5 296 320 396 597 ;
proc univariate data=Analysis outtable=Table noprint; var A1-A10; run;
次のステートメントは、各分析変数の平均、標準偏差などを含む図4.15のようなテーブルを作成します。
proc print data=Table label noobs; var _VAR_ _MIN_ _MEAN_ _MAX_ _STD_; label _VAR_='Analysis'; run;
| Test Scores for a College Course |
| Analysis | Minimum | Mean | Maximum | Standard Deviation |
|---|---|---|---|---|
| A1 | 0 | 90.76 | 178 | 57.024 |
| A2 | 2 | 167.32 | 267 | 81.628 |
| A3 | 52 | 224.56 | 372 | 96.525 |
| A4 | 27 | 258.08 | 493 | 145.218 |
| A5 | 25 | 283.48 | 524 | 157.033 |
| A6 | 2 | 107.48 | 196 | 52.437 |
| A7 | 11 | 153.20 | 296 | 90.031 |
| A8 | 18 | 217.08 | 393 | 130.031 |
| A9 | 45 | 280.68 | 498 | 140.943 |
| A10 | 11 | 243.24 | 597 | 178.799 |