FREQプロシジャ

TABLESステートメントでBINOMIALオプションを指定すると、FREQプロシジャは一元表の二項比率を計算します。 デフォルトでは、これは、出力に表示される最初の変数水準のオブザベーションの割合になります。なお、二項比率の別の水準を指定するには、LEVEL=オプションを使用します。二項比率は次のように計算されます。
ここで、![]() は最初の(または指定された)水準の度数であり、nは一元表の合計度数です。二項比率の標準誤差は次のように計算されます。
は最初の(または指定された)水準の度数であり、nは一元表の合計度数です。二項比率の標準誤差は次のように計算されます。
FREQプロシジャは、二項比率のWald信頼限界および正確な(Clopper-Pearson)信頼限界を提供します。または、BINOMIAL(CL=)オプションを指定して、二項比率の信頼限界の種類としてAgresti-Coull、Blaker、Jeffreys、正確なmid-p、尤度比、ロジット、Wilson (スコア)を要求することもできます。詳細は、信頼限界の各種類の説明で示されているリファレンスに加えて、Brown, Cai, and DasGupta (2001)、Agresti and Coull (1998)、およびNewcombe (1998b)を参照してください。
Wald漸近信頼限界は、二項分布の正規近似に基づきます。FREQプロシジャは、二項比率のWald信頼限界を次のように計算します。
ここで、![]() は、標準正規分布の
は、標準正規分布の![]() 番目のパーセント点です。信頼水準
番目のパーセント点です。信頼水準![]() は、ALPHA=オプションにより定義されます。この値はデフォルトで0.05であり、99%の信頼限界を生成します。
は、ALPHA=オプションにより定義されます。この値はデフォルトで0.05であり、99%の信頼限界を生成します。
CL=WALD(CORRECT)またはCORRECT binomial-optionを指定すると、FREQプロシジャは、Wald漸近信頼限界に![]() の連続性補正を含めます。この補正の目的は、正規近似と、離散的な二項分布との間の差異を調整することにあります。詳細は、Fleiss, Levin, and Paik (2003)を参照してください。二項比率の連続性補正Wald信頼限界は、次のように計算されます。
の連続性補正を含めます。この補正の目的は、正規近似と、離散的な二項分布との間の差異を調整することにあります。詳細は、Fleiss, Levin, and Paik (2003)を参照してください。二項比率の連続性補正Wald信頼限界は、次のように計算されます。
二項比率の正確な(Clopper-Pearson)信頼限界は、二項分布に基づく等尾部検定を反転することにより構成されます。この方法は、Clopper and Pearson (1934)により完成されたものです。正確な信頼限界![]() および
および![]() は、
は、![]() において、次の方程式を満たします。
において、次の方程式を満たします。
![\begin{eqnarray*} \sum _{x=n_1}^{n} \binom {n}{x} P_{\mi{L}}^{~ x} (1 - P_{\mi{L}})^{~ n-x} & = & \alpha /2 \\[0.1in] \sum _{x=0}^{n_1} \binom {n}{x} P_{\mi{U}}^{~ x} (1 - P_{\mi{U}})^{~ n-x} & = & \alpha /2 \end{eqnarray*}](images/procstat_freq0192.png)
![]() の場合、下側信頼限界がゼロになり、
の場合、下側信頼限界がゼロになり、![]() の場合、上側信頼限界が1になります。
の場合、上側信頼限界が1になります。
FREQプロシジャは、F分布を使用して、正確な(Clopper-Pearson)信頼限界を次のように計算します。
ここで、![]() は、自由度bおよびc を持つF分布の
は、自由度bおよびc を持つF分布の![]() 番目のパーセント点です。この式の導出についてはLeemis and Trivedi (1996)を参照してください。正確な二項比率の信頼限界の詳細については、Collett (1991)も参照してください。
番目のパーセント点です。この式の導出についてはLeemis and Trivedi (1996)を参照してください。正確な二項比率の信頼限界の詳細については、Collett (1991)も参照してください。
これは離散的な問題であるため、正確な(Clopper-Pearson)信頼区間の信頼係数(包含確率)
は、厳密には![]() ではなく最小で
ではなく最小で![]() となります。このため、この信頼区間は保守的となります。標本サイズが大きくない場合、実際の包含確率はターゲット値よりも非常に大きくなります。これらの信頼限界の性能に関する詳細は、Agresti and Coull (1998)、Brown, Cai, and DasGupta (2001)、およびLeemis and Trivedi (1996)を参照してください。
となります。このため、この信頼区間は保守的となります。標本サイズが大きくない場合、実際の包含確率はターゲット値よりも非常に大きくなります。これらの信頼限界の性能に関する詳細は、Agresti and Coull (1998)、Brown, Cai, and DasGupta (2001)、およびLeemis and Trivedi (1996)を参照してください。
CL=AGRESTICOULL binomial-optionを指定すると、FREQプロシジャは二項比率のAgresti-Coull信頼限界を次のように計算します。
ここで、
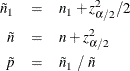
Agresti-Coull信頼区間は、標準Wald区間と同じ基盤を持ちますが、前者は![]() の代わりに
の代わりに ![]() を使用します。
を使用します。![]() である場合、
である場合、![]() の値は2に近くなるため、この区間は、Agresti and Coull (1998)が提唱した“成功2と失敗2”を追加するように調整されたWald区間になります。
の値は2に近くなるため、この区間は、Agresti and Coull (1998)が提唱した“成功2と失敗2”を追加するように調整されたWald区間になります。
CL=BLAKER binomial-optionを指定すると、FREQプロシジャは二項比率のBlaker信頼限界を計算します。これは、両側の正確なBlaker検定を反転することにより構成されます(Blaker, 2000)。![]() %のBlaker信頼区間は、検定統計量
%のBlaker信頼区間は、検定統計量![]() が選択域に入る、比率
が選択域に入る、比率![]() のすべての値により構成されます。
のすべての値により構成されます。
ここで、
また、Xは二項ランダム変数です。詳細は、Blaker (2000)を参照してください。
CL=JEFFREYS binomial-optionを指定すると、FREQプロシジャは二項比率のJeffreys信頼限界を次のように計算します。
ここで、![]() は、形状パラメータbおよびcを持つベータ分布の
は、形状パラメータbおよびcを持つベータ分布の![]() 番目のパーセント点です。
番目のパーセント点です。![]() の場合、下側信頼限界がゼロに設定され、
の場合、下側信頼限界がゼロに設定され、![]() の場合、上側信頼限界が1に設定されます。これは、二項比率の無情報Jeffreys事前分布に基づくEqual-tailed区間になります。詳細は、Brown, Cai, and DasGupta (2001)を参照してください。二項比率の推定のためのベータ事前分布に関する詳細は、Berger (1985)を参照してください。
の場合、上側信頼限界が1に設定されます。これは、二項比率の無情報Jeffreys事前分布に基づくEqual-tailed区間になります。詳細は、Brown, Cai, and DasGupta (2001)を参照してください。二項比率の推定のためのベータ事前分布に関する詳細は、Berger (1985)を参照してください。
CL=LIKELIHOODRATIO binomial-optionを指定すると、FREQプロシジャは、尤度比検定を反転することにより二項比率の尤度比信頼限界を計算します。
比率が![]() に等しい帰無仮説の尤度比検定統計量は、次のように表されます。
に等しい帰無仮説の尤度比検定統計量は、次のように表されます。
![]() %の尤度比信頼区間は、検定統計量
%の尤度比信頼区間は、検定統計量![]() が選択域に入る、
が選択域に入る、![]() のすべての値により構成されます。
のすべての値により構成されます。
ここで、![]() は、自由度が1であるカイ2乗分布の100
は、自由度が1であるカイ2乗分布の100![]() 番目のパーセント点です。FREQプロシジャは、反復計算により信頼限界を求めます。詳細は、Fleiss, Levin, and Paik (2003)、Brown, Cai, and DasGupta (2001)、Agresti (2013)、Newcombe (1998b)を参照してください。
番目のパーセント点です。FREQプロシジャは、反復計算により信頼限界を求めます。詳細は、Fleiss, Levin, and Paik (2003)、Brown, Cai, and DasGupta (2001)、Agresti (2013)、Newcombe (1998b)を参照してください。
CL=LOGIT binomial-optionを指定すると、FREQプロシジャは二項比率のロジット信頼限界を計算します。これはロジット変換![]() に基づいています。Yの近似信頼限界は、次のように計算されます。
に基づいています。Yの近似信頼限界は、次のように計算されます。
次のように、Yの信頼限界を反転して、二項比率pの![]() %ロジット信頼限界
%ロジット信頼限界![]() および
および![]() を求めます。
を求めます。
詳細は、Brown, Cai, and DasGupta (2001)およびKorn and Graubard (1998)を参照してください。
CL=MIDP binomial-optionを指定すると、FREQプロシジャは、mid-p裾領域を含む2つの片側二項検定を反転することにより二項比率の正確なmid-p信頼限界を計算します。mid-p手法では、観測された度数の確率が、Clopper-Pearson合計におけるその確率の半分に置き換えられます。詳細は、正確な(Clopper-Pearson)信頼限界のセクションを参照してください。 正確なmid-p信頼限界![]() および
および![]() は、次の方程式の解です。
は、次の方程式の解です。
![\begin{eqnarray*} \sum _{x=n_1+1}^{n} \binom {n}{x} P_{\mi{L}}^{~ x} (1 - P_{\mi{L}})^{~ n-x} ~ + ~ \frac{1}{2} \binom {n}{n_1} P_{\mi{L}}^{~ n_1} (1 - P_{\mi{L}})^{~ n-n_1} & = & \alpha /2 \\[0.1in] \sum _{x=0}^{n_1-1} \binom {n}{x} P_{\mi{U}}^{~ x} (1 - P_{\mi{U}})^{~ n-x} ~ + ~ \frac{1}{2} \binom {n}{n_1} P_{\mi{U}}^{~ n_1} (1 - P_{\mi{U}})^{~ n-n_1} & = & \alpha /2 \end{eqnarray*}](images/procstat_freq0220.png)
詳細は、Agresti and Gottard (2007)、Agresti (2013)、Newcombe (1998b)、Brown, Cai, and DasGupta (2001)を参照してください。
CL=WILSON binomial-optionを指定すると、FREQプロシジャは二項比率のWilson信頼限界を計算します。これはスコア信頼限界とも呼ばれます(Wilson, 1927)。この信頼限界は、帰無仮説の分散比を使用した正規検定(スコア検定)の反転に基づいています。 Wilson信頼限界は次の根になります。
これは次のように計算されます。
CL=WILSON(CORRECT)またはCORRECT binomial-optionを指定すると、FREQ プロシジャは連続性補正Wilson信頼限界を計算します。これは、次の根として計算されます。
Wilson区間は、Wald区間や正確な(Clopper-Pearson)区間よりも高い性能を持つことが証明されています。 詳細は、Agresti and Coull (1998)、Brown, Cai, and DasGupta (2001)、およびNewcombe (1998b)を参照してください。
BINOMIALオプションを指定すると、デフォルトで、二項比率の漸近等価性の検定が実施されます。また、binomial-optionsを指定することでも、二項比率の非劣性、優越性、同等性の検定を要求できます。EXACTステートメントでBINOMIALオプションを指定すると、FREQプロシジャは、binomial-optionsで要求された検定の正確なp値も計算します。
FREQプロシジャは、二項比率が![]() に等しいという仮説の漸近検定を計算します。ここで、
に等しいという仮説の漸近検定を計算します。ここで、![]() の値を指定するには、P=binomial-optionを使用します。P=にヌル値以外を指定すると、FREQプロシジャはデフォルト
の値を指定するには、P=binomial-optionを使用します。P=にヌル値以外を指定すると、FREQプロシジャはデフォルト![]() を使用します。二項検定は次のように計算されます。
を使用します。二項検定は次のように計算されます。
デフォルトでは、標準誤差は、帰無仮説の比率に基づいて次のように計算されます。
VAR=SAMPLE binomial-optionを指定すると、次のように、標本比率から標準誤差が計算されます。
CORRECT binomial-optionを指定すると、FREQプロシジャは、正規近似と離散的な二項分布間の差異を調整するために、漸近検定統計量に連続性補正を含めます。詳細は、Fleiss, Levin, and Paik (2003)を参照してください。![]() の連続性補正は、
の連続性補正は、![]() が正数である場合、検定統計量の分子から差し引かれます。それ以外の場合、連続性補正は同分子に追加されます。
が正数である場合、検定統計量の分子から差し引かれます。それ以外の場合、連続性補正は同分子に追加されます。
FREQプロシジャは、この検定の片側および両側のp値を計算します。検定統計量zがゼロ(帰無仮説の下でのその期待値)より大きい場合、FREQプロシジャは、右側p値を計算します。これは、帰無仮説の下で統計量の大きい値が発生する確率になります。小さい右側p値は、比率の真の値が![]() より大きいという対立仮説を支持します。この検定統計量がゼロ以下である場合、FREQプロシジャは、左側p値を計算します。これは、帰無仮説の下で統計量の小さな値が発生する確率になります。小さな左側p値は、比率の真の値が
より大きいという対立仮説を支持します。この検定統計量がゼロ以下である場合、FREQプロシジャは、左側p値を計算します。これは、帰無仮説の下で統計量の小さな値が発生する確率になります。小さな左側p値は、比率の真の値が![]() より小さいという対立仮説を支持します。片側のp値
より小さいという対立仮説を支持します。片側のp値![]() は、次のように計算されます。
は、次のように計算されます。
ここで、Zは標準正規分布に従います。両側のp値は、![]() として計算されます。
として計算されます。
EXACT ステートメントでBINOMIALオプションを指定すると、FREQプロシジャは、帰無仮説![]() の正確検定も計算します。正確検定を計算する場合、FREQプロシジャは次のような二項確率関数を使用します。
の正確検定も計算します。正確検定を計算する場合、FREQプロシジャは次のような二項確率関数を使用します。
ここで、変数Xはパラメータnおよび![]() を持つ二項分布に従います。左側p値
を持つ二項分布に従います。左側p値![]() を計算する場合、FREQプロシジャは、xの二項確率を、ゼロから
を計算する場合、FREQプロシジャは、xの二項確率を、ゼロから![]() まで合計します。右側p値
まで合計します。右側p値![]() を計算する場合、FREQプロシジャは、xの二項確率を
を計算する場合、FREQプロシジャは、xの二項確率を![]() からnまで合計します。正確な片側p値は、次に示すように、右側および左側p値の最小値となります。
からnまで合計します。正確な片側p値は、次に示すように、右側および左側p値の最小値となります。
両側のp値は、![]() として計算されます。
として計算されます。
NONINF binomial-optionを指定すると、FREQプロシジャは二項比率の非劣性の検定を実施します。非劣性の検定の帰無仮説は、次のようになります。
対立仮説は次のようになります。
ここで、![]() は非劣性のマージンであり、
は非劣性のマージンであり、![]() は帰無仮説の比率です。帰無仮説の棄却は、二項比率がヌル値に対して劣性でないことを示します。詳細は、Chow, Shao, and Wang (2003)を参照してください。
は帰無仮説の比率です。帰無仮説の棄却は、二項比率がヌル値に対して劣性でないことを示します。詳細は、Chow, Shao, and Wang (2003)を参照してください。
![]() の値を指定するには、MARGIN= binomial-optionを使用します。
の値を指定するには、MARGIN= binomial-optionを使用します。![]() を指定するには、P= binomial-optionを使用します。デフォルトでは、
を指定するには、P= binomial-optionを使用します。デフォルトでは、![]() および
および![]() になります。
になります。
FREQプロシジャは、非劣性の漸近Wald検定も実施します。検定統計量は次のように計算されます。
ここで、![]() は非劣性の限界であり、次の式が成り立ちます。
は非劣性の限界であり、次の式が成り立ちます。
デフォルトでは、標準誤差は、標本比率から次のように計算されます。
VAR=NULL binomial-optionを指定すると、標準誤差は非劣性の限界(帰無仮説の比率とマージンにより決定されるもの)に基づいて次のように計算されます。
CORRECT binomial-optionを指定すると、FREQプロシジャは漸近検定統計量zに連続性補正を含めます。![]() の連続性補正は、
の連続性補正は、![]() が正数である場合、検定統計量の分子から差し引かれます。それ以外の場合、連続性補正は同分子に追加されます。
が正数である場合、検定統計量の分子から差し引かれます。それ以外の場合、連続性補正は同分子に追加されます。
非劣性の検定のp値は次のようになります。
ここで、Zは標準正規分布を持ちます。
非劣性の分析の一部として、FREQプロシジャは、二項比率の漸近Wald信頼限界を計算します。
これらの信頼限界は、Wald信頼限界のセクションで示した方法で計算されますが、非劣性の検定統計量zの場合と同じ標準誤差(VAR=NULLまたはVAR=SAMPLE)を使用します。信頼係数は![]() %です(Schuirmann, 1999)。ALPHA=オプションを省略すると、非劣性の信頼限界はデフォルトで90%の信頼限界となります。この信頼限界を非劣性の限界
%です(Schuirmann, 1999)。ALPHA=オプションを省略すると、非劣性の信頼限界はデフォルトで90%の信頼限界となります。この信頼限界を非劣性の限界![]() と比較できます。
と比較できます。
EXACTステートメントでBINOMIALオプションを指定すると、FREQプロシジャは、二項比率の正確な非劣性の検定も計算します。正確なp値は、パラメータ![]() およびn値を持つ二項確率関数を使用して次のように計算されます。
およびn値を持つ二項確率関数を使用して次のように計算されます。
詳細については、Chow, Shao, and Wang (2003, p. 116)を参照してください。正確な二項統計量を要求する場合、FREQは、同等性の分析の表示の中に、二項比率の正確な(Clopper-Pearson)信頼限界も含めます。詳細は、正確な(Clopper-Pearson)信頼限界のセクションを参照してください。
SUP binomial-optionを指定すると、FREQプロシジャは、二項比率の優越性の検定を実施します。優越性の検定の帰無仮説は、次のように表されます。
対立仮説は次のようになります。
ここで、![]() 優越性のマージンであり、
優越性のマージンであり、![]() は帰無仮説の比率です。帰無仮説の棄却は、二項比率がヌル値に対して優越していることを示します。
は帰無仮説の比率です。帰無仮説の棄却は、二項比率がヌル値に対して優越していることを示します。
![]() の値を指定するには、MARGIN= binomial-optionを使用します。
の値を指定するには、MARGIN= binomial-optionを使用します。![]() の値を指定するには、P= binomial-optionを使用します。デフォルトでは、
の値を指定するには、P= binomial-optionを使用します。デフォルトでは、![]() および
および![]() になります。
になります。
優越性の分析は非劣性の分析と同じですが、帰無仮説で正のマージン値![]() を使用するところが違います。優越性の限界は
を使用するところが違います。優越性の限界は![]() に等しくなります。優越性の計算は非劣性の検定のセクションに示されている方法に従いますが、–
に等しくなります。優越性の計算は非劣性の検定のセクションに示されている方法に従いますが、–![]() の代わりに
の代わりに![]() を使用します。詳細は、Chow, Shao, and Wang (2003)を参照してください。
を使用します。詳細は、Chow, Shao, and Wang (2003)を参照してください。
EQUIV binomial-optionを指定すると、FREQプロシジャは、二項比率の同等性の検定を実施します。同等性の検定の帰無仮説は次のようになります。
対立仮説は次のようになります。
ここで、![]() は下限マージン、
は下限マージン、![]() は上限マージン、
は上限マージン、![]() は帰無仮説の比率です。帰無仮説の棄却は、二項比率がヌル値に対して同等であることを示します。詳細は、Chow, Shao, and Wang (2003)を参照してください。
は帰無仮説の比率です。帰無仮説の棄却は、二項比率がヌル値に対して同等であることを示します。詳細は、Chow, Shao, and Wang (2003)を参照してください。
マージン値![]() および
および![]() を指定するには、MARGIN= binomial-optionを使用します。MARGIN=を指定しない場合、FREQプロシジャはデフォルトの下限マージンおよび上限マージンとして、それぞれ–0.2および0.2を使用します。単一のマージン値
を指定するには、MARGIN= binomial-optionを使用します。MARGIN=を指定しない場合、FREQプロシジャはデフォルトの下限マージンおよび上限マージンとして、それぞれ–0.2および0.2を使用します。単一のマージン値![]() を指定すると、FREQプロシジャは下限マージンおよび上限マージンとして、それぞれ–
を指定すると、FREQプロシジャは下限マージンおよび上限マージンとして、それぞれ–![]() および
および![]() を使用します。帰無仮説の比率
を使用します。帰無仮説の比率![]() を指定するには、P= binomial-optionを使用します。デフォルトでは、
を指定するには、P= binomial-optionを使用します。デフォルトでは、![]() になります。
になります。
FREQプロシジャは、同等性の分析で、2つの片側検定(TOST)を計算します(Schuirmann, 1987)。TOST手法には、下限マージンの右側検定と、上限マージンの左側検定が含まれます。全体的なp値は、下側および上側の検定における2つのp値のうちの大きい方になります。
下限マージンの場合、漸近Wald検定統計量は次のように計算されます。
ここで、下側同等性限界は次のようになります。
デフォルトでは、標準誤差は、標本比率から次のように計算されます。
VAR=NULL binomial-optionを指定すると、標準誤差は下側同等性限界(帰無仮説の比率と下限マージンにより決定されるもの)に基づいて次のように計算されます。
CORRECT binomial-optionを指定すると、FREQプロシジャは漸近検定統計量![]() に連続性補正を含めます。
に連続性補正を含めます。![]() の連続性補正は、検定統計量
の連続性補正は、検定統計量![]() の分子が正数である場合、同分子から差し引かれます。それ以外の場合、連続性補正は同分子に追加されます。
の分子が正数である場合、同分子から差し引かれます。それ以外の場合、連続性補正は同分子に追加されます。
下限マージン検定のp値は次のようになります。
上限マージンの漸近検定も同様に計算されます。Wald検定統計量は次のように表されます。
ここで、同等性の上限は次のようになります。
デフォルトでは、標準誤差は、標本母集団から計算されます。VAR=NULL binomial-optionを指定すると、標準誤差は上側同等性限界に基づいて次のように計算されます。
CORRECT binomial-optionを指定すると、FREQプロシジャは漸近検定統計量![]() に
に![]() の連続性補正を含めます。
の連続性補正を含めます。
上限マージン検定のp値は次のようになります。
2つの片側検定(TOST)に基づく場合、同等性の検定の全体的なp値は、下限および上限マージン検定のp値以上になります。これは次のように表されます。
同等性の分析の一部として、FREQプロシジャは、二項比率の漸近Wald信頼限界を計算します。これらの信頼限界は、Wald信頼限界のセクションで示した方法で計算されますが、同等性の検定統計量の場合と同じ標準誤差(VAR=NULLまたはVAR=SAMPLE)を使用し、かつ![]() %の信頼係数を持ちます(Schuirmann, 1999)。ALPHA=を省略すると、これらはデフォルトで90%の信頼限界になります。VAR=NULLを指定すると、下限および上限マージン検定で、それぞれ帰無仮説の比率と対応する(下限または上限)マージンに基づいて、別々の標準誤差が計算されます。これらの信頼限界は、これらの2つの標準誤差の最大値を使用して計算されます。信頼限界を同等性の限界
%の信頼係数を持ちます(Schuirmann, 1999)。ALPHA=を省略すると、これらはデフォルトで90%の信頼限界になります。VAR=NULLを指定すると、下限および上限マージン検定で、それぞれ帰無仮説の比率と対応する(下限または上限)マージンに基づいて、別々の標準誤差が計算されます。これらの信頼限界は、これらの2つの標準誤差の最大値を使用して計算されます。信頼限界を同等性の限界![]() と比較できます。
と比較できます。
EXACTステートメントでBINOMIALオプションを指定すると、FREQプロシジャは、2つの片側正確検定(TOST)を使用した正確な同等性の検定も実施します。同プロシジャは、非劣性の検定のセクションに示されている二項確率関数を使用して上限および下限マージンの正確検定を計算します。同等性の検定の全体的な正確なp値は、下限および上限マージンの正確検定のp値において大きい方になります。正確検定を要求する場合、FREQプロシジャは、同等性の分析の表示に正確な(Clopper-Pearson)信頼限界も含めます。信頼係数は![]() %です(Schuirmann, 1999)。詳細は、正確な(Clopper-Pearson)信頼限界のセクションを参照してください。
%です(Schuirmann, 1999)。詳細は、正確な(Clopper-Pearson)信頼限界のセクションを参照してください。