FREQプロシジャ

FREQプロシジャを使うと、クロス集計表における連関性を検定するための各種の統計量を簡単に参照できます。
この例では、高校生が夏期特別学習プログラムのコースに申し込んだ場合を取り上げます。このコースには、ジャーナリズム、美術史、統計、グラフィックアート、コンピュータプログラミングが含まれています。申し込みを受理された生徒は、地元企業でのインターンシップがあるクラスとないクラスへとランダムに割り当てられます。表3.1は、この夏期特別学習プログラムに登録した生徒数を、性別およびクラス別(インターンシップがあるクラスへと割り当てられたかどうか)にまとめたものです。
表3.1: 夏期特別学習プログラムのデータ
|
Enrollment |
||||
|---|---|---|---|---|
|
Gender |
Internship |
Yes |
No |
Total |
|
boys |
yes |
35 |
29 |
64 |
|
boys |
no |
14 |
27 |
41 |
|
girls |
yes |
32 |
10 |
42 |
|
girls |
no |
53 |
23 |
76 |
SASデータセットSummerSchoolは、夏期特別学習プログラムのデータをセルカウントデータとして入力すること、または変数値の各組み合わせの度数カウントを提供することにより作成されます。SASデータセットSummerSchoolを作成するDATAステップステートメントは次のようになります。
data SummerSchool; input Gender $ Internship $ Enrollment $ Count @@; datalines; boys yes yes 35 boys yes no 29 boys no yes 14 boys no no 27 girls yes yes 32 girls yes no 10 girls no yes 53 girls no no 23 ;
変数Genderの値は‘boys’か‘girls’のいずれか、変数Internshipの値は‘yes‘か‘no’のいずれか、変数Enrollmentの値は‘yes’か‘no’のいずれかになります。変数Countの値は、データ値の各組み合わせに対応する生徒数になります。2個の連続するアットマーク(@@)は、1つのデータ行に複数のオブザベーションが含まれていることを示します。このDATAステップでは、各行に2つのオブザベーションが含まれています。
調査者は、インターンシップの有無と夏期特別学習プログラムの登録者数の間に連関性があるかどうかに興味を持っています。![]() 表における連関性を調べる統計量としては、Pearsonカイ2乗統計量が適しています。このような分析を行うPROC FREQステートメントは次のようになります。
表における連関性を調べる統計量としては、Pearsonカイ2乗統計量が適しています。このような分析を行うPROC FREQステートメントは次のようになります。
どの表の統計量を計算するかを指定するには、TABLESステートメントを使用します。計算したい統計量を指定するには、TABLESステートメントでスラッシュ(/)の後に対応するオプションを指定します。
proc freq data=SummerSchool order=data; tables Internship*Enrollment / chisq; weight Count; run;
ORDER=オプションを使うと、表の行と列に変数値が表示される順番を制御できます。デフォルトでは、各値は、フォーマットされていない値としてアルファベット順に並べられます。ORDER=DATAを指定すると、データは入力データセット内に現れるのと同じ順番で表示されます。ここで、値‘yes’はデータ内で値‘no’よりも先に現れるため、値‘yes’はいかなる表でも最初に表示されます。順序を制御するその他のオプションとしては、フォーマットされた値に従って値を並べるORDER=FORMATTEDや、度数カウントの高い順に値を並べるORDER=FREQUENCYがあります。
TABLESステートメント内のInternship*Enrollmentは、行変数がインターンシップの有無で、列変数がプログラムの登録者数であるような表を指定します。CHISQオプションは、これらの2変数間の連関性を調べるための統計量として、カイ2乗統計量を指定します。入力データはセルカウント形式であるため、WEIGHTステートメントが必要となります。WEIGHTステートメントでは、データ値の各組み合わせに対応する度数を提供する変数としてCountを指定します。
図3.1に、InternshipとEnrollmentのクロス集計表を示します。各セルのセルカウントの下には、表パーセンテージ、行パーセンテージ、列パーセンテージの値がそれぞれ表示されています。
たとえば、最初のセルには、インターンシップありのコースを申し込んだ生徒数は全体の63.21パーセントであり、申し込まなかった生徒数は全体の36.79パーセントであることが示されています。
図3.2に、CHISQオプションにより生成される統計量を示します。Pearsonカイ2乗統計量には'Chi-Square'というラベルが付けられており、自由度が1の場合、その値は0.8189になります。関連するp値は0.3655になります。これは、インターンシップの有無とプログラムの登録者数の間の連関性に関しては有意な根拠が存在しないことを意味します。その他のカイ2乗統計量は、同様の値を持つ、漸近的に等価な統計量です。その他の統計量(ファイ係数、一致係数、CramérのV)は、Pearsonカイ2乗統計量から導かれる連関性の統計量です。Fisherの正確検定では、両側のp値が0.4122となります。これも、インターンシップの有無とプログラムの登録者数の間に連関性がないことを示しています。
ここまでの分析では性別が無視されています。しかし、性別の調整を行った上で、プログラムの登録者数とインターンシップの有無の間に連関性があるかどうかを調べると面白いかもしれません。この問題を調べるには、表の集合の分析(この場合、男子からなる集合と女子からなる集合の分析)を実施します。この場合、Cochran-Mantel-Haenszel (CMH)統計量が適しています。この統計量を使うと、層化変数に対する調整を行った後で、行と列の間に連関性があるかどうかを調べることができます。この例では、性別(gender)により層化を行います。
この分析を行うPROC FREQステートメントは、先の分析に使用した同ステートメントと同様になりますが、TABLESステートメント内に第3の変数であるGenderが存在する点が異なります。3つ以上の変数をクロス集計する場合、2つの右端変数が表の行と列を構成し、残る左端変数が層化を決定することになります。
次のPROC FREQステートメントを使うことでも、クロス集計表の度数プロットを要求できます。FREQプロシジャは、ODS Graphicsを使用して、これらのプロットを同プロシジャ出力の一部として作成します。プロットを作成する前に、ODS Graphicsを有効にする必要があります。PLOTS(ONLY)=FREQPLOTオプションは、度数プロットを要求します。TWOWAY=CLUSTER plot-optionは、二元度数プロットのクラスタレイアウトを指定します。
ods graphics on;
proc freq data=SummerSchool;
tables Gender*Internship*Enrollment /
chisq cmh plots(only)=freqplot(twoway=cluster);
weight Count;
run;
ods graphics off;
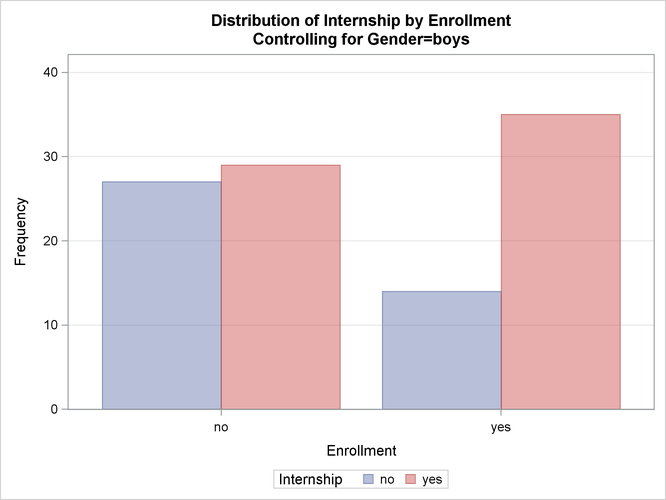
このPROC FREQステートメントを実行すると、最初に、行がInternshipで列がEnrollmentのクロス集計表が、男子生徒と女子生徒をそれぞれ対象として作成されます。これらの表ごとに、度数プロットとカイ2乗統計量が作成されます。図3.3、図3.4、図3.5に男子の集計結果を示します。男子生徒を対象としたカイ2乗統計量は、![]() の有意水準で有意となります。これは、インターンシップありのコースを申し込んだ男子生徒は、インターンシップなしのコースを申し込んだ男子生徒よりも登録率が高いことを示しています。
の有意水準で有意となります。これは、インターンシップありのコースを申し込んだ男子生徒は、インターンシップなしのコースを申し込んだ男子生徒よりも登録率が高いことを示しています。
図3.4に、男子生徒を対象とした、行がInternshipで列がEnrollmentの度数プロットを示します。デフォルトでは、度数プロットは棒グラフとして表示されます。PLOTS=オプションを使用すると、棒グラフの代わりに散布図を要求したり、バーの向きを垂直から水平に変更したり、尺度を度数からパーセントに変更したりできます。また、PLOTS=オプションを使用すると、別の二元レイアウト(積み上げ、垂直グループ、水平グループ)を指定したり、1次グループ化を列水準から行水準へと変更したりもできます。
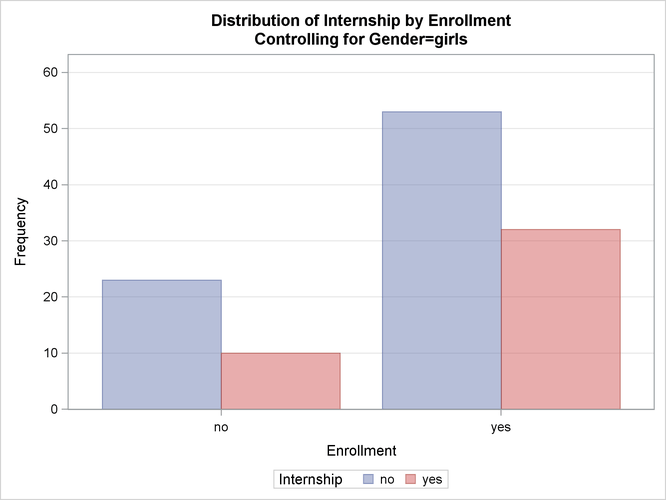
図3.6、図3.7、図3.8に、女子生徒を対象としたクロス集計表、度数プロット、カイ2乗統計量を示します。これらを見れば、女子生徒の場合には、インターンシップの有無とプログラムの登録者数との間に連関性の根拠が存在しないことが分かります。
これらの各表の結果は、他の変数(ここではGender)内の情報を説明する場合ではなく、情報を1つの表へと結合する場合に起こりがちな問題を示しています。図3.9に、CMH結果を示します。3つの要約(CMH)統計量が存在します。どの統計量を使用するかは、使用する![]() 表内での行や列の順序により異なります。ただし、
表内での行や列の順序により異なります。ただし、![]() 表の場合、順序は問題にならず、これら3つの統計量はすべて同じ値になります。CMH統計量は、連関性が存在しないという帰無仮説の下で、カイ2乗分布に従います。この例では、CMH統計量の値は、自由度が1の場合に4.0186になります。関連するp値は0.0450であり、これは水準
表の場合、順序は問題にならず、これら3つの統計量はすべて同じ値になります。CMH統計量は、連関性が存在しないという帰無仮説の下で、カイ2乗分布に従います。この例では、CMH統計量の値は、自由度が1の場合に4.0186になります。関連するp値は0.0450であり、これは水準![]() での有意な連関性を示しています。
での有意な連関性を示しています。
したがって、このデータにおける性別による影響を補正した場合には、インターンシップの有無とプログラムの登録者数との間に連関性が存在します。
ただし、性別を無視した場合には、連関性は存在しません。また、CMHオプションを指定すると、![]() 表の相対リスクやオッズ比の推定値や信頼限界、およびBreslow-Day検定のようなその他の統計量も生成されます。これらの結果は本セクションには示されていません。
表の相対リスクやオッズ比の推定値や信頼限界、およびBreslow-Day検定のようなその他の統計量も生成されます。これらの結果は本セクションには示されていません。