FREQプロシジャ

Cochran-Mantel-Haenszel統計量
TABLESステートメントでCMHオプションを指定すると、多次元表内の層変数に関する補正を行った上で、行変数と列変数間の関係の層化分析が行えます。たとえば、表要求がA*B*C*Dである場合、CMHオプションを指定すると、Aと Bに関する補正を行った上で、CとD間の関係の分析が行われます。層化分析は、AおよびBに対するパラメータ推定を強制せずに、それらに生じうる交絡的影響を補正する方法を提供します。
CMH分析はCochran-Mantel-Haenszel統計量を生成します。これには、相関統計量、ANOVA (行平均スコア)統計量、一般連関統計量が含まれます。 表の場合、CMHオプションを指定すると、共通オッズ比と共通相対リスクに関するMantel-Haenszel推定値およびロジット推定値に加えて、オッズ比の等質性に関するBreslow-Day検定も計算されます。
表の場合、CMHオプションを指定すると、共通オッズ比と共通相対リスクに関するMantel-Haenszel推定値およびロジット推定値に加えて、オッズ比の等質性に関するBreslow-Day検定も計算されます。
層化された表の場合、正確な統計量も提供されます。EXACTステートメントでEQORオプションを指定すると、FREQプロシジャは、等しいオッズ比に関するZelenの正確な検定を実施します。EXACTステートメントでCOMORオプションを指定すると、FREQプロシジャは、共通オッズ比に関する正確な信頼限界と、共通オッズ比が1に等しいかどうかの正確な検定を計算します。
層の数を で表し、
で表し、 により層をインデックス付けします。各層には、行変数Xと列変数Yを持つ分割表が含まれています。表
により層をインデックス付けします。各層には、行変数Xと列変数Yを持つ分割表が含まれています。表 の場合、行
の場合、行 列
列 のセル度数を
のセル度数を で表し、対応する行および列のマージンの合計をそれぞれ
で表し、対応する行および列のマージンの合計をそれぞれ および
および で、全体的な層の合計を
で、全体的な層の合計を で表します。
で表します。
Cochran-Mantel-Haenszel統計量の公式は行列で表した方がより簡単に定義できるため、次のような表記を使用します。ベクトルは転置 でない限り、列ベクトルであると推定されます。
でない限り、列ベクトルであると推定されます。
 |
層は独立であり、かつ各層のマージンの合計は固定であるとします。帰無仮説 は、いずれの層におけるXおよびY間にも連関性が存在しないこととなります。対応するモデルは、多重超幾何分布になります。これは、の下で、度数の期待値および共分散行列がそれぞれ次のようになることを意味します。
は、いずれの層におけるXおよびY間にも連関性が存在しないこととなります。対応するモデルは、多重超幾何分布になります。これは、の下で、度数の期待値および共分散行列がそれぞれ次のようになることを意味します。
 |
 |
ここで、
 |
ここで、 はKronecker積を表し、
はKronecker積を表し、 は主対角線上に
は主対角線上に の要素を含む対角行列です。
の要素を含む対角行列です。
一般化されたCMH統計量(Landis, Heyman, and Koch 1978)は次のように定義されます。
 |
ここで、
 |
 |
 |
|||
 |
|
 |
また、ここで、
 |
は、列スコア および行スコア
および行スコア に基づく固定された定数行列です。帰無仮説が真である場合、CMH統計量は、
に基づく固定された定数行列です。帰無仮説が真である場合、CMH統計量は、 の順位に等しい自由度を持つ漸近カイ2乗分布に従います。
の順位に等しい自由度を持つ漸近カイ2乗分布に従います。 が特異であることが判明した場合、FREQプロシジャはメッセージを表示し、CMH統計量の値に欠損値を設定します。
が特異であることが判明した場合、FREQプロシジャはメッセージを表示し、CMH統計量の値に欠損値を設定します。
FREQプロシジャは、一般化されたCMH統計量の公式を、統計量ごとに異なる行スコアと列スコアを組み合わせて使用することにより、3つのCMH統計量を計算します。FREQプロシジャが計算するCMH統計量は、相関統計量、ANOVA (行平均スコア)統計量、一般連関統計量です。これらの統計量を使用することで、連関性がないという帰無仮説を、各種の対立仮説に照らして検定できます。これらのCMH統計量の計算方法については、次の各セクションで説明します。
注意: CMH統計量は、一部の層の連関性のパターンが他の層により表示されるパターンの反対方向に存在する場合、連関性の検出能力が低くなります。このため、有意でないCMH統計量は、連関性がないことか、または他のパターンよりも優勢となるために十分な強度や整合性を持つ連関性のパターンが存在しないことを示唆します。
相関統計量
相関統計量は、Mantel and Haenszel (1959)およびMantel (1963)により一般化されたものであり、1つの自由度を持ち、Mantel-Haenszel統計量とも呼ばれます。
相関統計量の対立仮説は、少なくとも1つの層におけるXとYの間にリニアな連関が存在すること、になります。XまたはYのいずれかが順序(または区間)尺度でない場合、この統計量は無意味となります。
相関統計量を計算する場合、FREQプロシジャは、一般化されたCMH統計量の公式を、TABLESステートメントのSCORES=に指定された行スコアと列スコアと共に使用します。利用可能なスコアタイプに関する詳細は、スコアのセクションを参照してください。行スコアの行列は次元 を持ち、列スコアの行列は次元
を持ち、列スコアの行列は次元 を持ちます。
を持ちます。
存在する層が1つだけの場合、このCMH統計量は となります。ここで、
となります。ここで、 は
は と
と 間のPearson相関係数です。ノンパラメトリックな(RANKまたはRIDIT)スコアが指定された場合、この統計量は
間のPearson相関係数です。ノンパラメトリックな(RANKまたはRIDIT)スコアが指定された場合、この統計量は になります。ここで、
になります。ここで、 はXとYの間のSpearman順位相関係数です。複数の層が存在する場合、CMH統計量は層に関して調整済みの相関統計量になります。
はXとYの間のSpearman順位相関係数です。複数の層が存在する場合、CMH統計量は層に関して調整済みの相関統計量になります。
ANOVA (行の平均スコア)統計量
ANOVA統計量は、列変数Yが順序(または区間)尺度であり、Yの平均スコアが有意である場合にのみ利用できます。ANOVA統計量では、表の行ごとに平均スコアが計算されます。対立仮説は、少なくとも1つの層に関して 個の行の平均スコアが等しくないことになります。これは、同統計量がYの分布間における位置の差異に影響を受けやすいことを意味します。
個の行の平均スコアが等しくないことになります。これは、同統計量がYの分布間における位置の差異に影響を受けやすいことを意味します。
列スコアの行列は次元を持ちます。この列スコアはSCORES=オプションにより指定されます。
行スコアの行列は次元 を持ちます。これはFREQプロシジャにより次のように生成されます。
を持ちます。これはFREQプロシジャにより次のように生成されます。
 |
ここで、 は順位
は順位 の恒等行列であり、
の恒等行列であり、 は恒等行列の
は恒等行列の ベクトルです。この行列は、平均スコアに関するの独立対比の形成に関して影響を与えます。
ベクトルです。この行列は、平均スコアに関するの独立対比の形成に関して影響を与えます。
1つの層のみが存在する場合、このCMH統計量は本質的に分散分析(ANOVA)統計量となります。これは、独立変数Yに関する1元ANOVAから導かれる分散比率 統計量の関数であることを意味します。この場合、ノンパラメトリックスコアを指定すると、ANOVA統計量はKruskal-Wallis検定になります。
統計量の関数であることを意味します。この場合、ノンパラメトリックスコアを指定すると、ANOVA統計量はKruskal-Wallis検定になります。
複数の層が存在する場合、このCMH統計量は、層に関して調整済みのANOVAまたはKruskal-Wallis検定になります。各層の分割表内の行および列ごとにそれぞれ1つのサブジェクトが存在するという特殊なケースでは、このCMH統計量はFriedmanのカイ2乗統計量と同じになります。概要については例3.9を参照してください。
General Association統計量
一般連関統計量の対立仮説は、少なくとも1つの層において、XとYの間にある種の相関が存在すること、になります。この統計量はXまたはYが順序尺度であることを必要としないため、常に解釈可能となります。
一般連関統計量の場合、行列は、ANOVA統計量で使用される行列と同じになります。同様に、行列は次のように定義されます。
 |
FREQプロシジャは、両方のスコア行列を内部的に生成します。1つの層のみが存在する場合、一般連関CMH統計量は に削減されます。ここで、
に削減されます。ここで、 はPearsonカイ2乗統計量です。複数の層が存在する場合、CMH統計量は層に関して調整済みのPearsonカイ2乗統計量になります。層を通じてカイ2乗統計量を合計することにより、同様の調整を実施できます。ただし、後者の統計量は、結果として生成される自由度が
はPearsonカイ2乗統計量です。複数の層が存在する場合、CMH統計量は層に関して調整済みのPearsonカイ2乗統計量になります。層を通じてカイ2乗統計量を合計することにより、同様の調整を実施できます。ただし、後者の統計量は、結果として生成される自由度が のカイ2乗分布をサポートするために、各層で大きな標本サイズを必要とします。CMH統計量は、自由度として
のカイ2乗分布をサポートするために、各層で大きな標本サイズを必要とします。CMH統計量は、自由度として のみを持つため、全体的に大きな標本サイズのみを必要とします。
のみを持つため、全体的に大きな標本サイズのみを必要とします。
詳細は、Cochran (1954)、Mantel and Haenszel (1959)、Mantel (1963)、Birch (1965)、Landis, Heyman, and Koch (1978)を参照してください。
Mantel-Fleiss基準
TABLESステートメントでCMH(MANTELFLEISS)オプションを指定すると、FREQプロシジャは、層化された表のMantel-Fleiss基準を計算します。Mantel-Fleiss基準を使うことで、表のMantel-Haenszel統計量の分布に対するカイ2乗近似の妥当性を評価できます。詳細は、Mantel and Fleiss (1980)、Mantel and Haenszel (1959)、Stokes, Davis, and Koch (2000)、Dimitrienko et al. (2005) 詳細は、
Mantel-Fleiss基準は次のように計算されます。
 |
ここで、 は、表
は、表 内の行と列の間に連関性がないという帰無仮説の下での
内の行と列の間に連関性がないという帰無仮説の下での の期待値、
の期待値、 は表のセル度数が取りうる最小値、同様に
は表のセル度数が取りうる最小値、同様に は表のセル度数が取りうる最大値です。
は表のセル度数が取りうる最大値です。
 |
 |
 |
|||
 |
|
 |
|||
 |
|
 |
Mantel-Fleissガイドラインは、基準値が少なくとも5である場合、Mantel-Haenszel近似を受け入れます。基準値が5未満である場合、FREQプロシジャは警告を表示します。
修正されたオッズ比と相対リスク推定値
CMHオプションを指定すると、層化された表に対する修正されたオッズ比と相対リスク推定値を計算できます。これらの指標のそれぞれに関して、FREQプロシジャはMantel-Haenszel推定値とロジット推定値を計算します。これらの推定値は、行変数と列変数が両方とも2つのレベルを持つ場合、TABLESステートメントにおけるn元表の要求に対して適用されます。
たとえば、表の要求A*B*C*Dで、行変数Cおよび列変数Dの両方が2つのレベルを持つ場合、FREQプロシジャは、交絡変数AおよびBを補正した上でオッズ比と相対リスク推定値を計算します。
適切な指標の選択は、試験デザインにより異なります。ケースコントロール(後向き)試験の場合、オッズ比が適しています。cohort(予測)試験またはクロスセクション試験の場合、相対リスクが適しています。これらの指標に関する詳細は、2x2表に対するオッズ比と相対危険度のセクションを参照してください。
本セクション全体で、 は、標準正規分布の
は、標準正規分布の 番目のパーセント点を表します。
番目のパーセント点を表します。
オッズ比, ケースコントロールスタディ
FREQプロシジャは、層化された表に関する共通オッズ比のMantel-Haenszel推定値およびロジット推定値を計算します。
Mantel-Haenszel推定量 共通オッズ比のMantel-Haenszel推定値は次のように計算されます。
 |
これは、分母がゼロでない限り必ず計算されます。詳細は、Mantel and Haenszel (1959)およびAgresti (2002)を参照してください。
共通オッズ比の信頼限界を計算する場合、FREQプロシジャは に関するGreenland and Robins (1985)の分散推定値を使用します。 共通オッズ比に関する
に関するGreenland and Robins (1985)の分散推定値を使用します。 共通オッズ比に関する の信頼限界は、次のように計算されます。
の信頼限界は、次のように計算されます。
 |
ここで、
 |
|
 |
|||
 |
|
 |
|||
|
|
 |
|||
|
|
 |
Mantel-Haenszelのオッズ比推定量は、ロジット推定量に比べて、小さい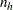 に影響を受けにくくなります。
に影響を受けにくくなります。
ロジット推定量 共通オッズ比に関する調整済みロジット推定値(Woolf 1955)は、次のように計算されます。
 |
および、対応する %の信頼限界は、
%の信頼限界は、
 |
ここで、 は層のオッズ比であり、次の式が成り立ちます。
は層のオッズ比であり、次の式が成り立ちます。
 |
層における任意の表のセル頻度がゼロである場合、FREQプロシジャはその層の各セルに を加算した後、ロジット推定値のおよび
を加算した後、ロジット推定値のおよび (Haldane 1955)を計算します。これが発生すると、このプロシジャは警告を表示します。
(Haldane 1955)を計算します。これが発生すると、このプロシジャは警告を表示します。
相対危険度, Cohortスタディ
FREQ プロシジャは、層化された表に関する共通相対リスクのMantel-Haenszel推定値およびロジット推定値を計算します。
Mantel-Haenszel推定量 列1の共通相対リスクに関するMantel-Haenszel推定値は次のように計算されます。
 |
これは、分母がゼロでない限り必ず計算されます。詳細は、Mantel and Haenszel (1959)およびAgresti (2002)を参照してください。
共通相対リスクの信頼限界を計算する場合、FREQプロシジャは、 に関するGreenland and Robins (1985)の分散推定値を使用します。共通相対リスクに関するの信頼限界は、次のように計算されます。
に関するGreenland and Robins (1985)の分散推定値を使用します。共通相対リスクに関するの信頼限界は、次のように計算されます。
 |
ここで、
 |
ロジット推定量 列1の共通相対リスクに関する調整済みロジット推定値は次のように計算されます。
 |
および、対応する%の信頼限界は、
 |
ここで、 は層に関する列1の相対リスク推定値であり、次の式が成り立ちます。
は層に関する列1の相対リスク推定値であり、次の式が成り立ちます。
 |
または がゼロである場合、FREQプロシジャはその層の各セルにを加算した後、ロジット推定値のおよびを計算します。これが発生すると、このプロシジャは警告を表示します。詳細は、Kleinbaum, Kupper, and Morgenstern (1982, Sections 17.4 and 17.5)を参照してください。
がゼロである場合、FREQプロシジャはその層の各セルにを加算した後、ロジット推定値のおよびを計算します。これが発生すると、このプロシジャは警告を表示します。詳細は、Kleinbaum, Kupper, and Morgenstern (1982, Sections 17.4 and 17.5)を参照してください。
オッズ比の等質性に対するBreslow-Day検定
CMHオプションを指定すると、FREQプロシジャは、層化された表に対するBreslow-Day検定を計算します。これは、 個の層でオッズ比が等しいという帰無仮説を検定します。この帰無仮説が真である場合、この統計量は、自由度が
個の層でオッズ比が等しいという帰無仮説を検定します。この帰無仮説が真である場合、この統計量は、自由度が のカイ2乗分布に近似的に従います。詳細は、Breslow and Day (1980)およびAgresti (2007)を参照してください。
のカイ2乗分布に近似的に従います。詳細は、Breslow and Day (1980)およびAgresti (2007)を参照してください。
Breslow-Day統計量は次のように計算されます。
 |
ここで、 および
および は、それぞれ期待値と分散を表します。合計には、ゼロの行または列を含む表は含まれません。
は、それぞれ期待値と分散を表します。合計には、ゼロの行または列を含む表は含まれません。 がゼロに等しいかまたは未定義の場合、FREQプロシジャはこの統計量を計算せずに、警告メッセージを表示します。
がゼロに等しいかまたは未定義の場合、FREQプロシジャはこの統計量を計算せずに、警告メッセージを表示します。
Breslow-Day検定が妥当であるためには、標本サイズが各層で相対的に大きくなければならず、しかも期待されるセルカウントの最低80%が5よりも大きいことが必要です。これは、 表に対するCochran-Mantel-Haenszel検定の要件よりも更に厳密な標本サイズ要件です。この場合、(全体的な標本サイズではなく)各層の標本サイズが相対的に大きいことが必要となります。Breslow-Day検定が妥当である場合でも、特定の対立仮説に照らした場合はそれほど強力でないことがあります。詳細はBreslow and Day (1980)を参照してください。
表に対するCochran-Mantel-Haenszel検定の要件よりも更に厳密な標本サイズ要件です。この場合、(全体的な標本サイズではなく)各層の標本サイズが相対的に大きいことが必要となります。Breslow-Day検定が妥当である場合でも、特定の対立仮説に照らした場合はそれほど強力でないことがあります。詳細はBreslow and Day (1980)を参照してください。
BDTオプションを指定すると、FREQプロシジャは、Taroneの調整を伴うBreslow-Day検定を計算します。これは、調整因子を から差し引くことで、結果として生成される統計量が漸近カイ2乗分布に従うようにします。Breslow-Day-Tarone統計量は次のように計算されます。
から差し引くことで、結果として生成される統計量が漸近カイ2乗分布に従うようにします。Breslow-Day-Tarone統計量は次のように計算されます。
 |
詳しくは、Tarone (1985), Jones et al. (1989)、Breslow (1996)を参照してください。
オッズ比の等質性に対するZelenの正確検定
EXACTステートメントでEQORオプションを指定すると、FREQプロシジャは、層化された表での等しいオッズ比に関するZelenの正確な検定を実施します。Zelenの検定は、等しいオッズ比に関するBreslow-Dayの漸近検定を正確にしたものです。Zelenの検定の参照集合には、観測された多次元クロス表と同じ行、列、層を持ち、かつ観測された表と同じセル の度数の合計を持つ、すべての可能な
の度数の合計を持つ、すべての可能な 表が含まれます。この検定統計量は、固定マージンに関する条件付きの観測された表の確率になります。これは、超幾何確率の積で表されます。
表が含まれます。この検定統計量は、固定マージンに関する条件付きの観測された表の確率になります。これは、超幾何確率の積で表されます。
Zelenの検定のp値は、観測された表確率以下のすべての表確率の合計になります。ここで、この合計は、固定マージンにより決定された参照集合内にあるすべての表と、セルの度数の観測された合計を通じて計算されます。この検定は、2元表に対するFisherの正確な検定に類似しています。詳細は、Zelen (1971)、Hirji (2006)、Agresti (1992)を参照してください。FREQプロシジャは、多項式の乗算アルゴリズムを使用してZelenの正確な検定を計算します。このアルゴリズムについては、Hirji et al. (1996)を参照してください。
共通オッズ比の正確な信頼限界
EXACTステートメントでCOMORオプションを指定すると、FREQプロシジャは、層化された表での共通オッズ比に関する正確な信頼限界を計算します。この計算では、すべての表でオッズ比が一定であることを仮定します。正確な信頼限界は、 の分布から作成されます。この分布の条件は、表の周辺度数です。
の分布から作成されます。この分布の条件は、表の周辺度数です。
これは離散的な問題であるため、これらの正確な信頼限界の信頼係数は厳密には( )ではなく、最小で()になります。このため、これらの信頼限界は保守的となります。詳細は、Agresti (1992)を参照してください。
)ではなく、最小で()になります。このため、これらの信頼限界は保守的となります。詳細は、Agresti (1992)を参照してください。
FREQプロシジャは、Vollset, Hirji, and Elashoff (1991)に基づくアルゴリズムを使用して、共通オッズ比に関する正確な信頼限界を計算します。詳細はMehta, Patel, and Gray (1985)を参照してください。
表のマージン合計に応じて、ランダム変数 が表セルの頻度を表すようにします。行合計が
が表セルの頻度を表すようにします。行合計が および
および で、列合計が
で、列合計が および
および である場合、
である場合、 の上限と下限である
の上限と下限である および
および は次のようになります。
は次のようになります。
 |
|
 |
|||
 |
|
 |
 は超幾何係数を表します。
は超幾何係数を表します。
 |
 は共通オッズ比を表します。の条件付き分布は次のようになります。
は共通オッズ比を表します。の条件付き分布は次のようになります。
 |
すべての表の合計は であり、
であり、 の上限および下限である
の上限および下限である および
および は次のようになります。
は次のようになります。
 |
合計の条件付き分布は次のようになります。
 |
ここで、
 |
 は、表でのセル(1,1)の頻度の合計を表します。次の2つの方程式を繰り返し解くことにより、共通オッズ比に関する上側および下側の信頼限界である
は、表でのセル(1,1)の頻度の合計を表します。次の2つの方程式を繰り返し解くことにより、共通オッズ比に関する上側および下側の信頼限界である および
および を決定できます。
を決定できます。
 |
|
 |
|||
 |
|
|
観測された合計が下限に等しい場合、FREQプロシジャは、下側信頼限界をゼロに設定し、レベル により上側信頼限界を決定します。同様に、観測された合計が上限に等しい場合、FREQプロシジャは、上側信頼限界を無限大に設定し、レベルにより下側信頼限界を決定します。
により上側信頼限界を決定します。同様に、観測された合計が上限に等しい場合、FREQプロシジャは、上側信頼限界を無限大に設定し、レベルにより下側信頼限界を決定します。
EXACTステートメントでCOMORオプションを指定すると、FREQプロシジャは、共通オッズ比が1に等しいという帰無仮説の下での正確な検定も計算します。 を設定すると、帰無仮説の下での合計の条件付き分布は次のようになります。
を設定すると、帰無仮説の下での合計の条件付き分布は次のようになります。
 |
この正確な検定の点確率は、帰無仮説の下での観測された合計の確率であり、これは層化された 表のマージンに関する条件に基づき、
表のマージンに関する条件に基づき、 で表されます。 帰無仮説の下でのの期待値は次のようになります。
で表されます。 帰無仮説の下でのの期待値は次のようになります。
 |
片側の正確なp値は、条件付き分布から または
または として計算されます。これは、観測された合計が
として計算されます。これは、観測された合計が より大きいか小さいかに応じて決定されます。
より大きいか小さいかに応じて決定されます。
 |
|
 |
|||
|
|
 |
FREQプロシジャは、この検定に関する両側のp値を、3つの異なる定義に従って計算します。両側のp値は、片側のp値を2倍したものとして計算されます。結果が1を超えた場合は1に設定されます。
 |
また、両側のp値は、観測された合計の点確率以下であるすべての確率の合計として計算されます。 のすべての取りうる値が合計されます。ここで、
のすべての取りうる値が合計されます。ここで、 です。
です。
 |
また、両側のp値は、片側のp値と分布の反対側の裾(期待値から等距離)にある対応する領域の合計としても計算されます。
 |