
Использование глубокого обучения для сегментации опухоли в медицинских изображениях
Автор: Джулия Гонг, студентка второго курса Стэнфордского университета, специальность «Математика и вычислительная наука», «Лингвистика»
Это второй пост в моей серии о проекте компьютерного зрения, над которым я работала в SAS. В моем предыдущем посте я рассказала о своем первоначальном исследовании и переживаниях по поводу проекта. В этой статье я расскажу, как доработала цели и начала работу над проектом по сегментации опухолей печени в 3D КТ-сканировании.
Теперь, когда я поняла, с какими инструментами буду работать, и прочувствовала конечную целью проекта, пришло время узнать конкретные вопросы, над которыми я буду работать:
- Формат изображения dicom: что это и чем он отличается от jpeg или png?
- Как выглядят данные?
- Как я могу получить к ним доступ, и после этого, как я могу их прочитать?
- Как выглядит печень? Что считается поражением?
- Каковы причины, по которым нужно извлечь эти поражения из компьютерной томографии?
- Как эти результирующие сегментации будут использоваться?
- Как я могу сделать эти результаты наиболее понятными для пользователя моего конечного продукта?
Эти контекстные вопросы так же важны, как и понимание инструментов, которые я собираюсь использовать. Они создают мотивацию для проекта во всех смыслах этого слова - конкретную причину, по которой проект важен для SAS и общества, а также внутреннюю мотивацию для меня, чтобы я хотела проект закончить.
Вопросы также поспособствовали доработке конечной цели проекта и шагов для ее достижения. Ответы на эти вопросы были решающей контрольной точкой для траектории проекта и ожидаемого конечного результата.
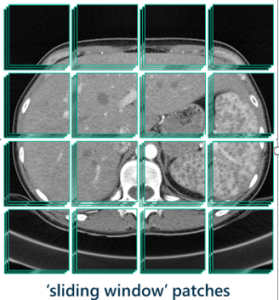
Мы решили, что моей целью будет разработка модели, которая использовала бы метод скользящего окна (sliding window), чтобы сегментировать поражения от исходных входных изображений и выводить окончательную черно-белую сегментацию, которая может быть видна пользователю.
Метод скользящего окна - техника компьютерного зрения, которая перемещает ограниченную рамку вокруг изображения в поисках объекта в этом фрагменте изображения при каждом его перемещении.
Когда все условности проекта были полностью обозначены, мне не терпелось начать.
Начнем с глубокого обучения
Моя конечная цель - создать систему, которая принимала бы входные данные и доставляла выходные, а основным компонентом этой системы является модель глубокого обучения. Поэтому, нужно построить модель, которая выполняла бы задачу классификации в сегментации изображения, используя трансферное обучение (transfer learning). С этого я и начала.
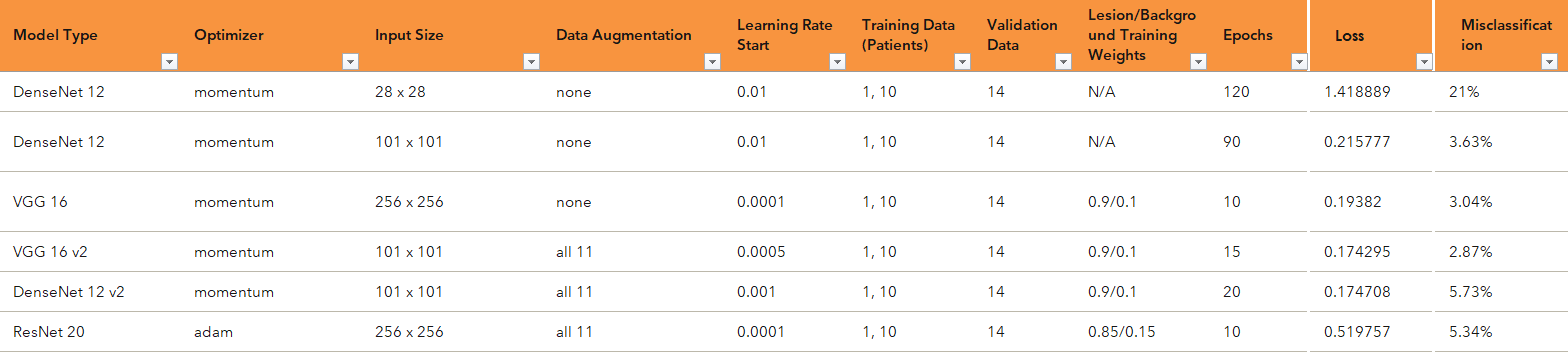
Краткий обзор записей, которые я вела. На этом этапе тестирования я запустила более 40 различных моделей.
Первое, что я узнала о глубоком обучении? Во многом это метод проб и ошибок. Предыдущие знания, обоснованные догадки, эмпирические данные и проверки гипотез - ваши лучшие друзья. Вы начинаете с архитектурной модели, взятой из литературы, пытаетесь повторить этот эксперимент, получить хороший результат и двигаться дальше.
Так как я использовала Python для Viya, первым делом я запустила несколько ноутбуков Jupyter для проведения этих экспериментов. Этот период проб и ошибок длился от трех до четырех недель. Я исследовала несколько различных моделей, предлагаемых в Viya: DenseNet, VGG и ResNet. Я вела электронную таблицу со всеми гиперпараметрами (различные аспекты сети, которые можно настроить, такие как скорость обучения, регуляризация L2 и количество запусков).
Как в случае с любой сложной проблемой, важно начинать с малого. В данном случае, я начала с более мелких моделей и данных, чтобы узнать, какие гиперпараметры будут оптимальными для этого конкретного типа данных. Джулия Гонг студентка второго курса Стэнфордского университета, специальность «Математика и вычислительная наука», «Лингвистика»
Как в случае с любой сложной проблемой, важно начинать с малого. В данном случае, я начала с более мелких моделей и данных, чтобы узнать, какие гиперпараметры будут оптимальными для этого конкретного типа данных. Хотя КТ-сканирование - это 3D-изображения с сотнями срезов, я начала с выбора только нескольких срезов из разных сканирований пациентов для обучения модели, а затем тестировала на одном срезе от другого пациента.
При завершении длительного процесса тестирования множества различных комбинаций гиперпараметров для каждой из моделей, я обнаружила, что модель VGG16 была наиболее эффективной, и нашла соответствующие гиперпараметры, которые максимизировали эффективность ее классификации.
В это время я была уже на полпути в рамках проекта, и придумала черновой набросок лучшей модели, которую можно было бы использовать в основе моего пайплайна. Но оставалось еще многое сделать, чтобы превратить этот единственный пайп в линию пайпов Скоро выйдет мой следующий пост, где я объясню, как я это сделала.
ОБ АВТОРЕ
Джулия Гонг - второкурсница в Стэнфордском университете, специальность «Математика и вычислительная наука», «Лингвистика». Она начала работать в SAS летом 2016 года, когда она создала программное обеспечение для обнаружения рака кожи на JMP с использованием методов анализа изображений и статистического моделирования. Летом 2017 года она использовала язык сценариев JMP для создания интерактивного пользовательского компоновщика R-надстроек для JMP. Летом 2018 года она создала сквозной автоматизированный пайплайн данных для сегментации опухолей печени при 3D-КТ-сканировании с использованием глубокого обучения и компьютерного зрения для анализа биомедицинских изображений в SAS Viya и CAS. Она получила признание на международных технологических конкурсах; любит публичные выступления, и ей нравится искать новые решения в таких областях, как искусственный интеллект, машинное обучение, лингвистика, охрана окружающей среды, медицина, сервис и искусство. Джулия надеется продолжить карьеру, которая объединит ее многочисленные интересы в области компьютерного зрения, искусственного интеллекта, медицины, обработки естественного языка, социального блага, образования и жизнеспособности.
Рекомендуем прочитать
-
 Finding COVID-19 answers with data and analyticsLearn how data plays a role in optimizing hospital resources, understanding disease spread, supply chain forecasting and scientific discoveries.
Finding COVID-19 answers with data and analyticsLearn how data plays a role in optimizing hospital resources, understanding disease spread, supply chain forecasting and scientific discoveries.
-
Спасти жизнь в период пандемии, оптимизируя медицинские ресурсыCleveland Clinic внедряет аналитику для борьбы с COVID-19, создавая инновационные модели, которые помогают прогнозировать количество пациентов, коек, доступность медицинского оборудования и многое другое.
-
5 советов по управлению данными, которые помогут вам улучшить работу с аналитикойСледуйте этим 5 рекомендациям по управлению данными, чтобы убедиться, что ваши бизнес-данные дают вам отличные результаты в рамках проведения аналитики.
